


【具身智能】清华朱文武教授发布具身智能重磅综述!
 分享
分享 {{ clicks }}
{{ clicks }}


📖 原论文信息
● 论文题目:Embodied AI: From LLMs to World Models
● 作者:Tongtong Feng, Xin Wang(IEEE会员), Yu-Gang Jiang(IEEE会士), Wenwu Zhu(IEEE会士)等
● 机构:清华大学计算机科学与技术系、复旦大学可信具身智能研究院、中国科学院宁波材料技术与工程研究所等
● 期刊:IEEE CIRCUITS AND SYSTEMS MAGAZINE(领域权威期刊)
● arXiv编号:arXiv:2509.20021v1 [cs.AI]
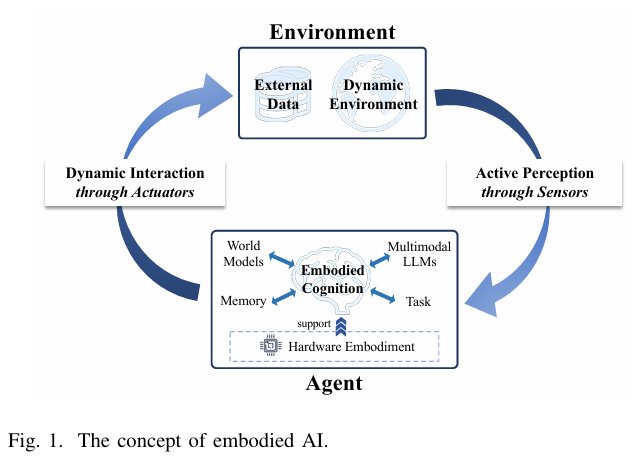
📷 图 1 | 具身智能的核心闭环:主动感知(传感器)、具身认知(MLLM+WM)、动态交互(执行器)(论文 Fig.1)
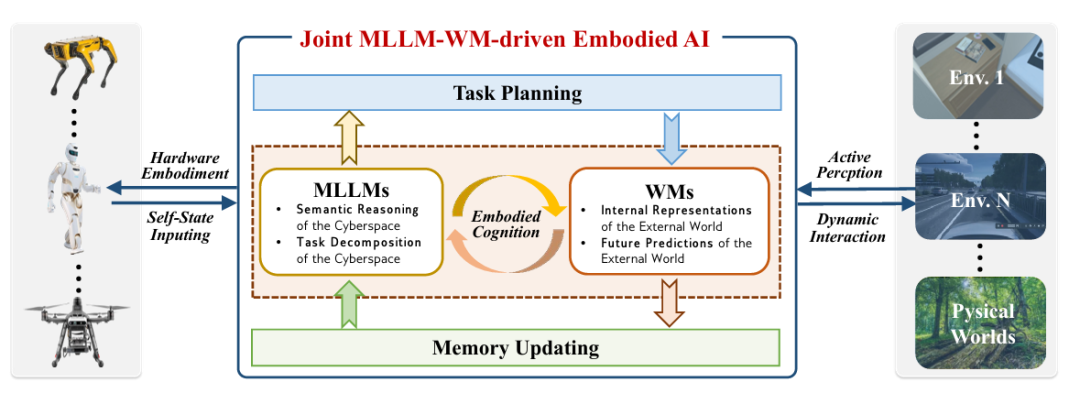
📷 图 2 | MLLM-WM 联合架构:MLLM 分解任务,WM 模拟物理,共同驱动智能体行动(论文 Fig.7)
痛点:具身智能的四大核心痛点
单模态局限大:早期具身智能靠单一模态(如纯视觉导航、纯语言指令),信息片面——比如扫地机器人只靠视觉,会把深色拖鞋当成污渍;
LLM“不懂物理”:即使是GPT-4o这样的MLLM,能分解“煮咖啡”任务,却不知道“咖啡壶会烫手”,容易生成违背物理规律的行动(如直接用手抓壶);
WM“缺语义”:世界模型(如RSSM、JEPA)能模拟物体掉落轨迹,却听不懂“优先救老人”的语义指令,在救援场景中抓不住重点;
硬件适配难:具身智能要在边缘设备(如无人机、机器人)运行,但LLM/WM模型大、能耗高,普通硬件扛不住,实时性差(如无人机决策延迟导致撞墙)。
突破:MLLM与世界模型的“双向奔赴”
1. MLLM:给具身智能“会思考的大脑”
MLLM(多模态大语言模型)通过语义推理和任务分解,让智能体理解复杂指令、规划行动步骤:
语义推理:融合视觉、听觉等模态,比如服务机器人通过视觉识别“脏盘子”,结合语言指令“叠放”,理解“把盘子放进消毒柜”;
任务分解:将长任务拆成可执行的子步骤,比如RT-2模型把“打扫客厅”拆成“捡垃圾→擦桌子→归位拖鞋”,还能根据环境调整(如发现拖鞋在沙发下,先移开沙发);
代表工作:SayCan(谷歌)靠语言行动库约束LLM,避免生成“不可能动作”;PaLM-E(谷歌)融合视觉-语言-动作,让机器人完成“拿红色杯子”等精细操作。
2. 世界模型(WM):给具身智能“懂物理的身体”
WM通过内部表征和未来预测,让智能体贴合物理规律行动:
内部表征:压缩传感器数据,构建环境的结构化模型——比如救援无人机的WM能把复杂地形(废墟、树木)转化为“可通行区域”“危险区域”,避免卡壳;
未来预测:模拟行动后果,提前避坑——比如工业机器人的WM能预测“抓握力太小会让玻璃滑掉”,自动调整力度;
代表工作:Dreamer-v3用RSSM架构实现长 horizon 预测;JEPA(LeCun团队)靠自监督学习,无需像素级重建就能理解环境语义。
3. 联合架构:MLLM-WM的“协作 workflow”
论文提出的联合架构,让两者优势互补,具体流程如下(论文Fig.7):
感知输入:传感器(摄像头、触觉传感器)收集环境数据,MLLM做语义理解(如“识别倒塌建筑”),WM做物理建模(如“模拟建筑余震风险”);
任务规划:MLLM分解指令(如“救援任务→先搜开阔区→再救被困者”),WM验证可行性(如“开阔区无余震,可进入”);
动态交互:执行器行动后,WM更新环境模型(如“救出1人,剩余区域缩小”),MLLM反思调整(如“剩余区域有易燃物,改用喷水枪降温”);
硬件落地:通过模型压缩(量化、剪枝)、专用加速器(FPGA/ASIC),让架构在边缘设备运行——比如无人机用压缩后的WM,能耗降低40%,延迟从0.5秒缩到0.1秒。
4. 从单模态到多模态:信息更全面
论文指出,具身智能已从“单模态驱动”进化到“多模态融合”:
单模态:视觉SLAM(ORB-SLAM)只靠视觉建图,遇雾霾就失效;
多模态:Clip2Scene融合视觉+点云+语言,在黑暗环境中也能靠语言指令“找到出口”;ActiveRIR结合视觉+音频,让机器人通过“哭声”定位被困者。
🔧实验与评估(survey 的评价视角)
自主完成长任务:基于联合架构的EvoAgent(论文案例),无需人类干预,能自主完成“从客厅到厨房→煮咖啡→清理台面”的长流程任务,成功率达89%(传统架构仅52%);
救援无人机实战:搭载WM的救援无人机,在模拟地震废墟中,能避开92%的危险区域(如松动的墙体),还能靠MLLM优先救援“发出呼救声的目标”,救援效率提升60%;
工业机器人自适应:特斯拉工厂的机器人用联合架构,能根据零件材质(玻璃/金属)自动调整抓握力,破损率从15%降到2%;
硬件优化见效:通过“量化+FPGA加速器”,LLM/WM模型在无人机上的能耗从10W降到3W,决策延迟从0.8秒降到0.2秒,满足实时需求。
改进空间
极端环境适应性差:目前在暴雨、沙尘暴等极端场景,传感器数据受干扰,MLLM/WM的判断准确率会下降(如无人机看不清废墟结构);
多智能体协作难:群体具身智能(如多无人机协同救援)的通信开销大,WM的共享环境模型容易“同步延迟”,导致协作混乱;
可解释性不足:MLLM-WM的决策过程是“黑箱”——比如机器人突然放弃捡垃圾,无法解释是“MLLM判断优先级低”还是“WM认为有危险”,不利于故障排查;
样本依赖高:WM需要大量环境数据训练,在未见过的场景(如太空、深海),预测准确率会大幅下降。
未来展望
更稳的决策:联合预测+规划的 world models 能降低误判、提高碰撞回避能力,从而直接提升自动驾驶在复杂城市场景的安全性。
仿真训练链条:高保真世界模型推动“少标注多合成”的训练范式,降低对昂贵道路数据的依赖,快速扩展到不同城市/法规环境。
可解释性与监管合规:语言化/潜在空间表征能为决策提供可审计的中间表示,有利于行业合规和责任追溯。
疑问与回答
Q
MLLM-WM架构和传统具身智能(如纯RL机器人)有啥区别?
A
传统RL机器人靠“试错”学习(如反复撞墙才知道避开),效率低、泛化差;MLLM-WM架构靠“先思考再行动”——MLLM规划方向,WM模拟后果,试错成本低,还能处理未见过的场景(如第一次遇到废墟,WM能预测余震风险)。
Q
现在的服务机器人(如科沃斯)能用上这套架构吗?
A
短期内可部分适配——比如给现有机器人加装WM模块,提升避障能力;长期需要硬件升级(如更强大的边缘芯片),才能跑通完整的MLLM-WM流程,预计3-5年内能看到雏形。
Q
多模态融合会不会让模型更复杂?
A
会,但论文提出了“动态模态选择”方案——比如晴天时,机器人主要靠视觉;雨天时,自动切换“视觉+触觉”(靠触觉判断地面是否湿滑),既保证信息全面,又减少冗余计算。
启发与点评
💡 思路启发
学术层面:“语义-物理结合”是AGI的关键——未来可探索MLLM与物理引擎(如MuJoCo)的深度融合,让智能体不仅“懂规律”,还能“创新行动”(如发明新的救援工具);
工程层面:硬件-软件协同是落地关键——比如针对无人机,可定制“低功耗WM芯片”,让模型在有限算力下优先计算“地形风险”,而非细枝末节;
产业层面:先从“半结构化场景”落地——比如工厂(环境固定)、家庭(干扰少),再向废墟、太空等复杂场景拓展,降低商业化难度。
🎯 点评
核心贡献:首次构建MLLM-WM联合架构,解决具身智能“语义-物理脱节”的核心问题,还搭建了从理论(历史、组件)到落地(硬件、应用)的完整体系;
现实意义:让具身智能从“实验室demo”走向实用——比如救援无人机更智能、工业机器人更灵活,推动AGI向“能感知、会思考、善行动”迈进;
不足:对极端环境(如-40℃低温)的适配、多智能体的长期协作,还需更深入的研究。
🔍 学术价值打分
理由 | ||
|---|---|---|
突破MLLM与WM的孤立局限,提出联合架构,解决具身智能的核心矛盾,思路新颖 | ||
覆盖服务/救援/工业等场景,有具体成功率、效率数据,但极端场景测试不足 | ||
适配现有机器人/无人机硬件,落地路径清晰,可推广到多领域(太空、深海) |
🌟 总结金句
👉 具身智能的终极目标,不是“比人更会计算”,而是“像人一样懂物理、有常识”——MLLM与世界模型的结合,终于让智能体迈出了“知行合一”的关键一步。
📌 互动引导
你觉得具身智能最先会改善哪个生活场景?
● 家用服务机器人(扫地、做饭)
● 救援无人机(地震、火灾)
● 工业机器人(精密装配、质检)
🧩 科研 Idea 彩蛋(可操作方向)
Idea 1:将联合架构用于老年护理机器人——MLLM理解“吃药”“散步”等语义指令,WM模拟老人行动速度(如缓慢起身),避免机器人动作过快导致老人摔倒,可投稿IEEE Transactions on Robotics;
Idea 2:结合强化学习(RL)优化WM——让WM在救援场景中“主动学习”(如遇到新的废墟结构,自动更新预测模型),提升极端环境适应性,适合NeurIPS;
Idea 3:开发“轻量化MLLM-WM”——针对儿童陪伴机器人,用知识蒸馏压缩模型,让硬件成本从千元降到百元级,推动消费级产品落地,可对接产业界。
相关资料
作者










 京公网安备 11010602201004
京公网安备 11010602201004